I’ve been trying to get Wireguard to run on my oldish VServer. The kernel is either too old, or the provider hasn’t compiled it with the necessary modules. wireguard-go seemed like a solution for this problem. However, I did not want to install a Go toolchain on the server, so I built the program locally. Go places a premium on easy distribution, so this might have worked.
However, it didn’t: Wireguard-go uses network functions, and so the resulting binaries aren’t statically linked by default. What’s worse is that the resulting file depends on a version of glibc that isn’t on my server. I saw this as an opportunity to dive deeper into the innards of ELF files, and learn something new.
Note: After learning something new, I found out I could have just disabled cgo with export CGO_ENABLED=0 and gotten a statically linked binary that probably would have worked. But that’s not what we’re here for!
Static vs. dynamic linking
Go software is supposed to be portable, because it’s linked statically (in most cases). This means that the code for all dependencies is included in the binary, and not required later. This is not the “standard” model for Linux software: Dynamic linking allows updating dependencies without recompiling your program. Additionally, dependencies are shared, which means that two programs with the same dependency can both use the shared library. Static linking, on the other claw, duplicates dependencies for every program, and requires recompilation when updating dependencies.
However, static linking reduces the faff when deploying software. Instead of having to install multiple dependencies, just copy over the compiled file and run it. This works for most pure Go programs. When using cgo to interface with C code, all bets are off. When deploying such a program, you have to have the dependencies of the correct version available on the host systems.
In our specific case, the glibc version differed between my server (2.28) and my laptop (2.33).
Problem #1: The dynamic linker (aka. loader)
The dynamic linker (or “loader”) is, broadly speaking, the interpreter for executable files. It takes an executable, which on Linux, is going to be an ELF file and puts stuff into memory where it belongs. After that, control passes to the C library to prepare some more. The C library then finally jumps to your main function, which is where your code lives. The dynamic linker is a shared library at /lib/ld-linux.so.… and gets loaded by every dynamically linked program.
The dynamic linker is not to be confused with the “normal” linker, which is generally called as the last step in a program’s compilation. Its responsibility is to move stuff around, check symbol references, and much more. If you’re interested in more background, the book Linkers & Loaders should provide ample detail. I should probably read it myself at some point☺.
The dynamic linker is set at compile time by the “normal” linker, which makes sense, since their innards are closely related. This means that you need to use the same dynamic linker on your development as well as your host system. So we need to modify the dynamic linker in the ELF file to make it run on our ancient server.
The interpreter is contained twice in the executable, once in a segment in the program header, and once in a section. Let’s take a short detour, and use the poke editor to look at the executable file and where it stores the dynamic linker information.
Detour: GNU poke
I’ve been doing most of my exploration of ELF files with the GNU poke interactive editor. It comes with predefined ELF mappings, so we can actually have a poke1 at an example ELF file. Poke should be packaged for most distributions. Install it, and open your ls binary with poke /bin/ls. You’ll get some output, but that doesn’t interest us. Now, we’ll load the predefined ELF maps, and get us a reference to the ELF header.
(poke) load elf
(poke) var f = Elf64_File @ 0#B;
This creates a bidirectional “view”, or “mapping”, in poke parlance. What we are doing is overlaying a view (in this case, an ELF file) over our unstructured memory. The base address of the mapping is 0, since we start at the beginning of the file.
We can access and modify elements of this view, which will also transparently edit our file. But for now, we’re only here for looking. Let’s get the program headers and section headers. Thankfully, the preloaded ELF support has already done this for us. You can get a list of all program headers with f.phdr, and the list of section headers with f.shdr2. Remember that the interpreter is stored in two places: A section with the name “.interp”, and a program header with the type value PT_INTERP.
Let’s get the section first. Again, the ELF type thankfully provides us with a function get_sections_by_name to get this section. We take element zero of the list, since there’s only one section. To get the name, we take a string starting at the offset of the section into the ELF file.
(poke) var interp_section = f.get_sections_by_name(".interp")[0]
(poke) string @ interp_section.sh_offset
"/lib64/ld-linux-x86-64.so.2"
There we are, that’s the interpreter section. As for the program header, we need to do some searching. Poke is a fully fledged programming language, which allows us to do this (I’ve had to add the cast, because the constants are not typed as you’d expect):
(poke) for (phdr in f.phdr where phdr.p_type == (PT_INTERP as Elf_Word)) { printf("%v\n", string @ phdr.p_offset); }
"/lib64/ld-linux-x86-64.so.2"
We’re looping through all program headers, and print the string at the offset when we find one with the correct type.
We could modify our interpreter now, but let’s do that later.
Detour end.
The dynamic linker, reinterpreted
Now that we’ve seen where the interpreters are stored in the ELF file, we could modify them via poke. However, there’s an easier way. The NixOS project has developed a tool called patchelf to modify dynamic executables. NixOS needs this functionality to support their unique approach to building software.
We’re going to use it for slightly less useful purposes, and modify the interpreter in our binary. But first, what’s the error?
jeeger@server:~$ ./binary
-bash: ./binary: No such file or directory
jeeger@server:~$ ls -la binary
-rwxr-xr-x 1 jeeger jeeger 3809581 Jan 26 15:45 binary
This is incredibly confusing, since the file is obviously there. It’s also executable. The problem is that the interpreter is not present. What’s our interpreter?
jeeger@laptop:~$ patchelf --print-interpreter binary
/nix/store/s9qbqh7gzacs7h68b2jfmn9l6q4jwfjz-glibc-2.33-59/lib/ld-linux-x86-64.so.2
That’s not going to fly on a non-nix system. Let’s change the interpreter with patchelf to something that works on other systems as well.
jeeger@laptop:~$ patchelf --set-interpreter /lib64/ld-linux-x86-64.so.2 binary
Now, we can copy it back to the server and try to run it again.
jeeger@server:~$ ./binary
./binary: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.32' not found (required by ./binary)
That’s better! Problem 1: fixedcircumvented. This is not going to work if the different loaders aren’t compatible. Did I mention this article shouldn’t be a guide for production?
Problem #2: GLIBC versions
Now, when we run our binary, we get a GLIBC version warning. Now, we want to patch the GLIBC version to not require a new version, but try and run with the old version. I didn’t go deep into the intricacies of dynamic linking – all I wanted to do was modify the version information that’s in our binary so it’ll try and run with the version that’s on the server. The program will probably crash, but eh. I’m not missing out on this learning opportunity.
First, what are the version requirements of our binary? objdump to the rescue!
jeeger@laptop:~$ objdump -T binary
binary: file format elf64-x86-64
DYNAMIC SYMBOL TABLE:
00000000004aed40 g DF .text 0000000000000063 Base crosscall2
00000000004aed00 g DF .text 0000000000000037 Base _cgo_panic
0000000000462dc0 g DF .text 0000000000000019 Base _cgo_topofstack
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 __errno_location
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 getaddrinfo
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 freeaddrinfo
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 gai_strerror
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 stderr
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 fwrite
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 vfprintf
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 fputc
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 abort
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_mutex_lock
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.3.2 pthread_cond_wait
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_mutex_unlock
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.3.2 pthread_cond_broadcast
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_create
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 nanosleep
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_detach
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 strerror
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 fprintf
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 free
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 malloc
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_attr_init
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_attr_getstacksize
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 pthread_attr_destroy
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 sigfillset
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.32 pthread_sigmask
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 mmap
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 munmap
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 setenv
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 unsetenv
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 sigemptyset
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 sigaddset
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 sigaction
0000000000000000 DO *UND* 0000000000000000 GLIBC_2.2.5 sigismember
Okay, that’s all fine and dandy. The only thing that’s too new is pthread_sigmask, which requires glibc version 2.32. That’s too new, so let’s get to patching it. First, we need to know how version requirements are stored in the ELF file. I found two references for this, which both seem somewhat out of date: The Solaris implementation information from Oracle is a bit easier to understand, but not fully correct for Linux. The Linux Standard Base reference is correct, but harder to read. There’s also an article, which introduced me to a very useful readelf invocation. Let’s try it on our binary.
jeeger@laptop:~$ readelf -W --version-info binary
Version symbols section '.gnu.version' contains 37 entries:
Addr: 0x0000000000599d00 Offset: 0x199d00 Link: 11 (.dynsym)
000: 0 (*local*) 1 (*global*) 1 (*global*) 1 (*global*)
004: 5 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5)
008: 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5)
00c: 3 (GLIBC_2.2.5) 5 (GLIBC_2.2.5) 4 (GLIBC_2.3.2) 5 (GLIBC_2.2.5)
010: 4 (GLIBC_2.3.2) 5 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 5 (GLIBC_2.2.5)
014: 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5)
018: 3 (GLIBC_2.2.5) 5 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5)
01c: 2 (GLIBC_2.32) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5)
020: 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 3 (GLIBC_2.2.5) 5 (GLIBC_2.2.5)
024: 3 (GLIBC_2.2.5)
Version needs section '.gnu.version_r' contains 2 entries:
Addr: 0x0000000000599d60 Offset: 0x199d60 Link: 10 (.dynstr)
000000: Version: 1 File: libc.so.6 Cnt: 2
0x0010: Name: GLIBC_2.32 Flags: none Version: 2
0x0020: Name: GLIBC_2.2.5 Flags: none Version: 3
0x0030: Version: 1 File: libpthread.so.0 Cnt: 2
0x0040: Name: GLIBC_2.3.2 Flags: none Version: 4
0x0050: Name: GLIBC_2.2.5 Flags: none Version: 5
This makes the information from the reference a bit more clear. There’s a version definition section, which contains versions for exported symbols (we’re not interested in those), and another “Version needs” section which contains the info we’re interested in.
We can see that there’s multiple dependency definitions per required library. If I’m interpreting this correctly, only the first one is interesting for us. We’ll modify them all, just to be sure. Let’s go a’poking again!
Update: From my reading of the above link, and seeing readelf tie required versions to imported symbols, my understanding of multiple aux entries is now that the vna_other field is referenced from the version table in the .gnu.version section.
The version table is an array of Elf_Half values with the same length as the .dynsym symbol table. The value in the .version table assigns some value to the symbol with the same index.
If the symbol is exported, the corresponding version is found in the .gnu.version_d section, if it’s imported, it’s found in the .gnu.version_r section. The version itself is found by going through all the aux values and selecting that which has a vna_other value that corresponds to the value in the .gnu.version section. I’ve tried to illustrate this in the figure below.
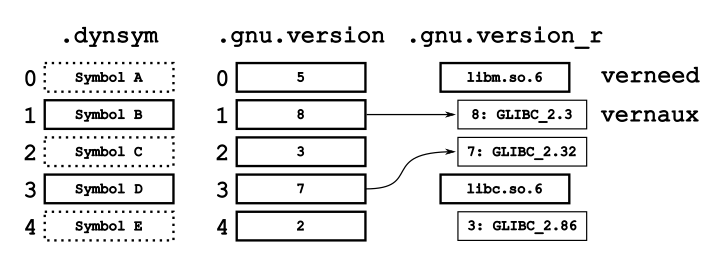
Assignment of versions from the .dynsym section via the .gnu.version section.
In the example, the .dynsym section contains 5 symbols (never mind their layout). Dashed symbols are exported, or hidden, and we’re not interested in those. The .gnu.version section assigns each of these a “version identifier”. For required symbols, we look for the “version identifier” in the .gnu.version_r section by finding the vna_other field with the same version identifier. In this example, symbol A needs to be present in the libm.so.6 library with a version of GLIBC_2.3, while symbol D needs to be available with a version of GLIBC_2.32.
Poking the version
This is where Poke having a fully fledged programming language really pays off. First things first: We’ll have to define some types for the version entries. Fortunately, this is pretty simple, and we can just paste the C definitions into a new .pk file. But: Poke is smart, and we can get a much better view into our structs using some Poke features. Let’s define the types first:
|
|
This is mostly just the definition copied from the spec, extended with some Poke features. First, the offset type in line 8 specifies that something is an offset (duh). It also specifies how large the offset value is (one Elf_Word), and what unit the offset is in (bytes). Line 16 contains a “constraint”, which specifies a requirement that must always be true. If it’s not, mapping the struct will fail. We’ll use this later on to map multiple verneed structures. Line 21 contains an array definition. It specifies an array of vn_cnt Elf_veraux structs starting from the vn_aux offset. This requires that the aux structures are laid out continuously in memory, but that seems to be the case for our binary.
How do we get the version strings and filenames? The Solaris and LSB specs differ here: In LSB (and on my system), the strings are contained in a special section in the ELF file that’s referenced from the .gnu.version_r section’s sh_link field.
We can find that field with poke as follows:
(poke) load elf
(poke) var f = Elf64_File @ 0#B;
(poke) var version_section = f.get_sections_by_name(".gnu.version_r")[0];
(poke) var name_offset f.shdr[version_section.sh_link].sh_offset;
We get the version_r section, access it’s sh_link field which contains an index into all section headers to get the right section. That section’s offset is the base address for the strings referenced in the structures above.
To get a verneed’s filename, we can now run string @ name_offset + verneed.vn_file to give us the filename.
We now have almost everything in place. We can loop through the versions, find the one we want to replace, and update its vna_name to the correct offset. Since this is a bit tedious, I’ve not included code samples here. The full pickle is available here.
Two excerpts are interesting nonetheless.
Finding the new offset
To set the new version, we need to set the vna_name field to a new offset. Finding this offset is a bit tedious:
|
|
One interesting poke feature is used in line 5: Poke arrays can take either a count of elements, as in other programming languages, or a size. When an offset is provided, poke tries to fill the array with elements matching exactly the required size. In this example, poke tries to map exactly enough zero-terminated strings to get to a total size of name_size. Poke array size can also be left unspecified, in which case poke tries to map the element repeatedly until a constraint fails. We use this in our pickle to read all verneed structures without having to follow the vn_next pointers, relying on the version always being equal to 1.
We’re iterating over all version strings and adding up the size of the strings we’ve seen until we find the one we’re looking for, and store the required offset.
There should be a better way to do this in Poke, but I couldn’t find it, feedback is welcome.
ELF hashing
Unfortunately, just setting a new vna_name doesn’t work. We also have to update the vna_hash. Otherwise, the hash comparison will fail, and we’ll have a non-running binary again.
The hash value is used to speed up versioning to skip comparing multiple strings. The hash implementation used is, luckily enough, available at Wikipedia. I’ve reimplemented it in Poke as elf_Hash.
Putting it all together
var needs = Elf_verneed[] @ version_section.sh_offset;
for (need in needs) {
for (aux in need.aux) {
var name = string @ name_offset + aux.vna_name;
printf("Name: %v, hash: %v\n", name, aux.vna_hash);
if (name == version_from) {
print("Replacing dependency version.\n");
aux.vna_name = offset;
aux.vna_hash = new_hash;
};
};
};
Here, we’re doing the array mapping I’ve alluded to above to collect all verneed structures. This might fail spectacularly if there happens to be memory with another 1 in the place of vn_version, but everything else isn’t reliable by any standard anyways.
We iterate through all version needs, iterate through all auxes, getting the name. If it’s equal to the name we want to replace, we modify the aux structure to point to a new version. We also update the hash. Note that this assignment immediately modifies the file we’re editing – that’s the magic of poke mappings at work.
Conclusion
With these parts in hand, we can modify our existing binary to run on an old server. Note that this doesn’t mean that the binary will run correctly. When it calls pthread_sigmask, everything will probably crash and burn. But, as I’ve said before, this was mostly a meandering exploration of ELF files and their structure. No fitness for production is implied, beware of nasal demons, &c.
If you have any feedback, you can mastodon me.